| idade_anos | raca | escol | |
|---|---|---|---|
| 5 | 39 | parda | superior |
| 6 | 34 | branca | superior |
| 8 | 29 | branca | medio |
| 11 | 28 | branca | medio |
| 13 | 37 | parda | fund2 |
| 16 | 27 | branca | medio |
| 17 | 44 | branca | medio |
| 23 | 31 | branca | medio |
| 24 | 33 | amarela | medio |
| 25 | 25 | parda | medio |
3 Tabulação de dados
Na sessão 5 obtivemos nosso primeiro contato com os vários tipos e estrutura de dados no qual basearemos nossas análises, integer, Character, Complex etc. Além das possíveis formas de disposição desses dados nos atuais softwares de programação, tomando como exemplos os DataFrames apresentados para a linguagem R.
3.1 Variáveis
Os objetos apresentados, ou variáveis, podem ser denotados como o armazenamento de informações sobre a característica de interesse a respeito de cada unidade amostral, variáveis socioeconômicas como raça, renda e escolaridade são um ótimo exemplo. As variáveis podem ser divididas em dois tipos:
Variáveis Qualitativas: cujos valores podem ser separados por categorias não numéricas. Sendo chamadas de variáveis qualitativas ordinais quando há presença de uma ordenação entre as categorias (Ex.: Escolaridade), e variáveis qualitativas nominais caso contrário (Ex.: Raça, Sexo)
Variáveis Quantitativas: onde os valores são expressos em números resultantes de uma contagem ou mensuração. Podendo ser quantitativas discretas, quando resultam de um conjunto finito ou enumerável de possíveis valores (Ex.: Número de vitórias ou de filhos), ou ainda variáveis quantitativas continuas quando assumem valores em uma escala continua (Ex.: Peso, Altura).
Observe as 10 unidades amostrais para as variáveis da base de dados COVID-19 para melhor compreensão, onde a idade representa variável quantitativa discreta, a raça represeta qualitativa nominal e a escolaridade é relativa a qualitativa ordinal.
Podemos olhar uma variável por outra perspectiva, assumindo um outro tipo de classificação. Isso pode soar um pouco estranho a princípio, mas olher o exemplo a seguir para melhor compreensão, considere a variável idade, podemos transformar em faixas de idade para classificação em criança, jovem, adulto e idoso. Observe:
#criacao da variavel classificacao
classificacao <- idade_anos |>
lapply(function(x) ifelse(x < 12, 'crianca',
ifelse(x < 25, 'jovem',
ifelse( x < 60 ,'adulto','idoso'))))
#tabela concatenando idade e classificacao
classificacao |>
unlist() |>
cbind(idade_anos) |>
head(10) |> knitr::kable()| idade_anos | |
|---|---|
| jovem | 24 |
| adulto | 31 |
| adulto | 27 |
| jovem | 20 |
| adulto | 39 |
| adulto | 34 |
| adulto | 34 |
| adulto | 29 |
| adulto | 44 |
| adulto | 27 |
Agora, temos uma variável categórica ordinal.
3.2 Como tabular
É perceptível, até mesmo quando trabalhamos com DataFrames e matrizes, a forma proposta de visualização e armazenamento dessas variáveis. Por colunas onde cada coluna representa uma das características (no nosso exemplo, idade, raça e escolaridade).
Fazemos isso de forma a facilitar nossa análise, sendo cada linha um indíviduo e, cada uma das observações dentro dessa linha, suas características.
Assim como discutido, podemos obter nossas bases de dados de diversas fontes, como planilhas excel, arquivos .csv, bases SQL, ou até mesmo criá-las no nosso próprio R script com a função data.frame() como já apresentado. Por ser mais intuitivo e mais utilizado no dia a dia, vamos tomar o excel para exemplificar todo o processo. Você irá notar que o processo é realizado de forma bem simples.
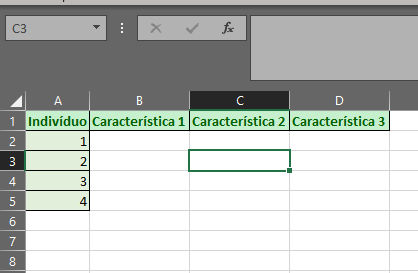
Cada uma das células receberá um valor x referente a alguma característica indicada pela coluna e um indivíduo representado pela linha, em nosso caso temos 3 características para cada uma das 4 observações.
3.3 Alguns problemas no meio do caminho
É valido ressaltar que é possível se deparar com alguns problemas que talvez possam vir a ser solucionados da maneira errada.
A forma como tabulamos nossos dados pode vir a ser um facilitar ou empecilho em nossas análises, um belo exemplo é a forma citada anteriormente de classificação dos dados ou transformação para que sejam salvos em alguma outra categoria, como faixa etária ou idade.
Outro problema é quando trabalhamos com dados que possas vir a ter mais de uma resposta. Por exemplo: Quais sintomas estava sentindo? O melhor a se fazer nesse caso é criar uma coluna para cada um dos possíveis sintomas.
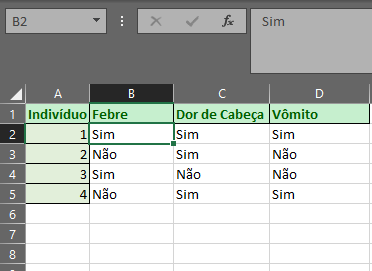
Uma outra forma seria:
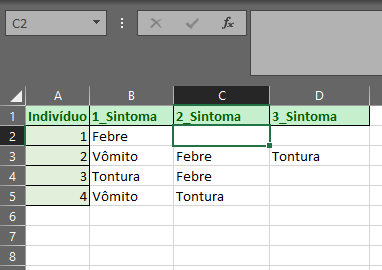
Devemos lembrar sempre de anexar um ID ou forma de identificação única para cada uma das observações. É possível criar uma ou trabalhar com alguma já existente, um exemplo de uma já existente é o próprio CPF ou RG quando trabalhamos com pessoas.
Vale ressaltar outras boas práticas ao realizar a tabulação:
Se trabalhando com Excel ou Softwares parecidos, deixe a planilha apenas com a tabela de dados, evite armazenar na mesma planilha várias informações avulssas que não façam parte da sua tabela;
No R conseguimos especificar qual planilha de um arquivo
.xlsxqueremos transferir, porém pode vir a ser um pouco confuso as vezes, então é sugerido deixar todas as suas informações em uma única tabela em uma única planilha;Padronização é extremamente importante, salve todos os dados para cada coluna em apenas um determinado formato (Ex.: Coluna Idade - Integer, Coluna Raça - Character), lembrando sempre de manter um padrão de medida (cm, L), variáveis do tipo categórico tambem precisam de padronização (Evite coisas como: Não, nao, n, N, não);
Cuidado ao classificar dados faltantes, uma prática errada é preencher esses dados com 0, isso pode vir a atrapalhar toda sua análise
Foi citado CPF como forma de identificação, mas pode haver casos em que teremos mais de uma linha contendo um mesmo indivíduo dependendo do nosso tipo de dados. Ou seja, esteja atento para que não haja duplicidade de variável identificadora ou
ID.