Capítulo2 Introdução
A Estatística é a ciência que engloba métodos para coleta, organização, descrição, análise e interpretação de dados, sendo estes estruturados (as estruturas usuais de bases de dados) ou não estruturados (como arquivos de textos, páginas da web, e-mails, mídias sociais etc). Assim, podemos dizer que por meio da Estatística transformamos dados em informações para o auxílio de tomadas de decisões em situações de incerteza.
Devido à alta capacidade de armazenamento das mídias e ao uso generalizado de computadores, muitos dados estão sendo coletados e o mundo dependendo cada vez mais deles para criar conhecimento, obter informações relevantes e prever melhor o futuro. No seu livro Homo Deus, de 2016, Yuval Noah Harari argumenta que todos as estruturas políticas e sociais podem ser vistas como sistemas de processamento de dados e que daí surge a religião dataísmo: “O dataísmo declara que o universo consiste em fluxos de dados e que o valor de qualquer fenômeno ou entidade é determinada pela contribuição que dá para o processamento de dados” (https://pt.wikipedia.org/wiki/Dataísmo).
Na pesquisa médica, em especial, são realizados estudos experimentais ou observacionais, levando à coleção de dados em que o objetivo da investigação é responder a uma questão científica. Para exemplificar esse ponto, vamos considerar um problema da área da medicina obstétrica que consiste no estudo da idade gestacional do parto em gestações gemelares (de gêmeos).
A importância de se estudar a idade gestacional do parto em gestação gemelares se deve pelo elevado risco de prematuridade (parto antes de 37 semanas) em gestações múltiplas. Entre as mulheres com gestação gemelar, o parto prematuro que ocorre antes das 37 semanas é observado em mais de 50% dos casos e quase 12% antes de 32 semanas completas de gestação (Silva 1995). Devido a esse fato, observa-se uma taxa de mortalidade neonatal nas gestações gemelares de 6,4 vezes maior que nas gestações únicas (único feto), e essa taxa se mantém inalterada desde o ano de 2000 (Maternal 2009).
O trabalho de parto é consequência de eventos fisiológicos, como por exemplo, o predomínio da ação estrogênica em relação à progesterônica. A progesterona é um hormônio fundamental para a manutenção da gravidez, e um declínio na ação da progesterona é fundamental para o início do parto na maioria das espécies de mamíferos, incluindo os primatas (Astle, Slater, and Thornton 2003). A progesterona está presente na natureza, em humanos e em animais (ovários, placenta, testículos e adrenal). Os seus precursores estão presentes nos vegetais, como a soja e o inhame, e constituem a principal fonte de produção da progesterona natural comercializada (Oliveira et al. 2016).
Em gestações com colo curto, também com risco de prematuridade, o uso de progesterona comercializada é um tratamento conhecido na literatura para diminuir o risco de prematuridade. No projeto liderado pela obstetra e profa. Dra. Maria de Lourdes Brizot (http://lattes.cnpq.br/6273300603065618), a pergunta que se deseja responder é:
O uso de progesterona diminui o risco de prematuridade em gestações gemelares?
Para responder essa pergunta, foi realizado um estudo prospectivo, randomizado, duplo ensaio cego controlado por placebo que envolveu 390 gestações gemelares sem histórico de parto prematuro. Mulheres com gestações gemelares entre 18 e 21 semanas e 6 dias de gestação foram designadas aleatoriamente em um de dois grupos:
Tratamento com progesterona - progesterona vaginal diária (200 mg) até 34 semanas e 6 dias de gestação (ou até o parto se este ocorreu antes de 35 semanas).
Tratamento placebo - óvulos de placebo até 34 semanas e 6 dias de gestação (ou até o parto se este ocorreu antes de 35 semanas).
Um comentário importante: placebo é toda e qualquer substância sem propriedades farmacológicas, administrada a pessoas ou grupo de pessoas como se tivesse propriedades terapêuticas. A palavra “placebo” vem do latim placere, que significa “agradar.” Neste material não entraremos em detalhes sobre tipos de estudo. Para esse assunto e maiores discussões sobre placebo, recomendamos ver os slides “Tipos de estudos” disponível em https://daslab-ufes.github.io/materiais/.
Voltando ao problema da progesterona, houve 6 perdas de segmento no grupo progesterona e 4 perdas de segmento no grupo placebo, resultando em \(n=189\) no grupo progesterona e \(n=191\) no grupo placebo.
A variação nos dados faz com que a resposta não seja óbvia. Precisamos de ferramentas estatísticas para determinar se a diferença é tão grande que devemos rejeitar a noção de que foi devido ao acaso.
No caso do estudo da progesterona, a diferença na proporção de prematuridade do grupo progesterona e do grupo controle é devido a flutuações aleatórias ou é um indício de que o uso de progesterona é um protocolo mais eficiente?
A seguir são apresentadas as bases de dados que consideramos no decorrer deste material.
2.1 Bases de dados
2.1.1 Gestações gemelares
A base de dados fictícia de gestações gemelares é baseada no estudo citado anteriormente sobre o efeito do uso de progesterona em gestações gemelares. Sabe-se que os históricos obstétrico e clínico da gestante e informações da gestação também podem influenciar a idade gestacional do parto, e por esse motivo também foram avaliados. São as características observadas:
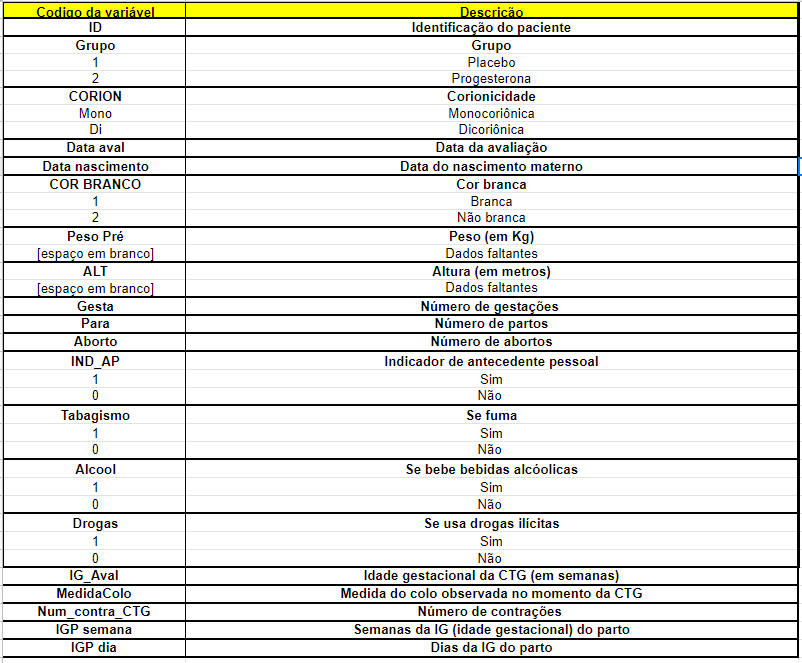
Figure 2.1: Variáveis da base de dados gestações gemelares.
A seguir está o exemplo de como os dados de 5 indivíduos estão tabulados.
| ID | Grupo | CORION | Data aval | Data nascimento | COR BRANCO | Peso Pré | ALT | Gesta | Para | Aborto | IND_AP | Tabagismo | Alcool | Drogas | IG_Aval | MedidaColo | Num_contra_CTG | IGP semana | IGP dia | oi |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 18 | 2 | Di | 2016-03-21 | 1987-03-29 | 1 | 80.0 | 1.59 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 31.43 | 20.00 | 7 | 37 | 5 | NA |
| 19 | 2 | Di | 2016-02-17 | 1980-02-26 | 1 | NA | 1.62 | 4 | 3 | 0 | 0 | 1 | 1 | 0 | 27.00 | 6.60 | 2 | 33 | 2 | NA |
| 20 | 1 | Di | 2017-12-14 | 1998-12-19 | 2 | 61.0 | 1.64 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 33.71 | 7.00 | 10 | 35 | 3 | NA |
| 21 | 1 | Mono | 2017-04-23 | 1988-04-30 | 1 | 44.0 | 1.64 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 83.86 | 5.83 | 8 | 36 | 3 | NA |
| 22 | 2 | Di | 2016-03-21 | 1995-03-27 | 2 | 100.0 | 1.59 | 2 | 1 | 0 | 1 | 0 | 1 | 0 | 33.71 | 12.10 | 3 | 37 | 6 | NA |
Essa base de dados está disponível em https://daslab-ufes.github.io/materiais/, chamado de “Dados gemelares.”
2.1.2 Gestações gemelares - depressão e amamentação
Essa base de dados fictícia apresenta informações sobre depressão e amamentação das mesmas observações consideradas na base de dados Gestações gemelares, apresentada no item anterior.
O questionário de depressão EDPS foi respondido pelas gestantes no primeiro trimestre gestacional e respondido novamente pelas mesmas gestantes no quarto mês pós-parto. Esse questionário retorna um escore (de 0 a 30 pontos), em que quanto maior seu valor, maior indicador de depressão.
Sobre a amamentação, foram divididos três grupos a depender das orientações sobre a amamentação recebidas durante o pré-natal. O grupo 1 é formado pelas gestantes que tiveram mentorias durante o pré-natal e acompanhamento nas amamentações das primeiras semanas; o grupo 2 é formado pelas gestações que receberam apenas orientações durante o pré-natal e no grupo 3 estão as gestantes que não receberam orientações sobre amamentação.
São as características observadas:

Figure 2.2: Variáveis da base de dados gestações gemelares - depressão e amamentação.
A seguir está o exemplo de como os dados de 5 indivíduos estão tabulados.
| ID | EPDS_antes | EPDS_depois | EDPS_antes_SN | EDPS_depois_SN | Grupo_amamentacao | Tempo_amamentacao_meses |
|---|---|---|---|---|---|---|
| 18 | 2 | 1 | 0 | 0 | 1 | 10 |
| 19 | 6 | 3 | 0 | 0 | 2 | 4 |
| 20 | 10 | 8 | 0 | 0 | 2 | 15 |
| 21 | 15 | 18 | 1 | 1 | 2 | 11 |
| 22 | 3 | 4 | 0 | 0 | 2 | 8 |
Essa base de dados está disponível em https://daslab-ufes.github.io/materiais/, chamado de “Dados gemelares - depressão e amamentação.”
2.2 Sobre o software R
R é um ambiente computacional e uma linguagem de programação para manipulação, análise e visualização de dados. É considerado um dos melhores ambiente computacional para essa finalidade. O R é mantido pela R Development Core Team e está disponível para diferentes sistemas operacionais: Linux, Mac e Windows.
O software é livre, ou seja, gratuito, com código aberto em uma linguagem acessível. Nele, estão implementadas muitas metodologias estatísticas. Muitas dessas fazem parte do ambiente base de R e outras acompanham o ambiente sob a forma de pacotes, o que torna o R altamente expansível. Os pacotes são bibliotecas com dados e funções para diferentes áreas do conhecimento relacionados à estatística e áreas afins, devidamente documentados.
O R possui uma comunidade extremamente ativa, engajada desde o aprimoramento de ferramentas e desenvolvimento de novas bibliotecas, até o suporte aos usuários. Sobre o desenvolvimento de novas bibliotecas, um pesquisador em Estatística que desenvolve um novo modelo estatístico pode disponibilizá-lo em um pacote acessível a que se interessam pelo modelo.
Além disso, a disponibilidade e compartilhamento da pesquisa em um pacote no R é uma boa prática quando falamos de reprodutibilidade na Ciência. Ainda nesse ponto, realizar as análises de uma pesquisa aplicada em um programa livre e acessível a todos é um dos principais pontos para permitir reprodutibilidade.
Ao optar por programar em R também implica na escolha de uma IDE (Integrated Development Environment) que, na grande maioria dos casos, será o RStudio. O RStudio é um conjunto de ferramentas integradas projetadas para editar e executar os códigos em R. Assim, quando for o interesse utilizar o R, só precisa abrir o RStudio (R é automaticamente carregado).
Para instalação do R e do RStudio, veja a Seção que segue.
2.3 Instalação R e RStudio
2.3.1 Instalação R
Nessa Seção, vamos apresentar como instalar o R e o RStudio para os três sistemas operacionais: Windows, MAC e Linux, respectivamente.
2.3.1.1 Para Windows
Os passos para instalar o R quando o sistema operacional é Windows são os seguintes:
- Entre neste link para acessar a página do R e clique em Download, como no link destacado em retângulo vermelho na Figura 2.3. Note que o 3.6.1 é o número da versão mais recente disponível no momento da construção desse material (5/7/19).
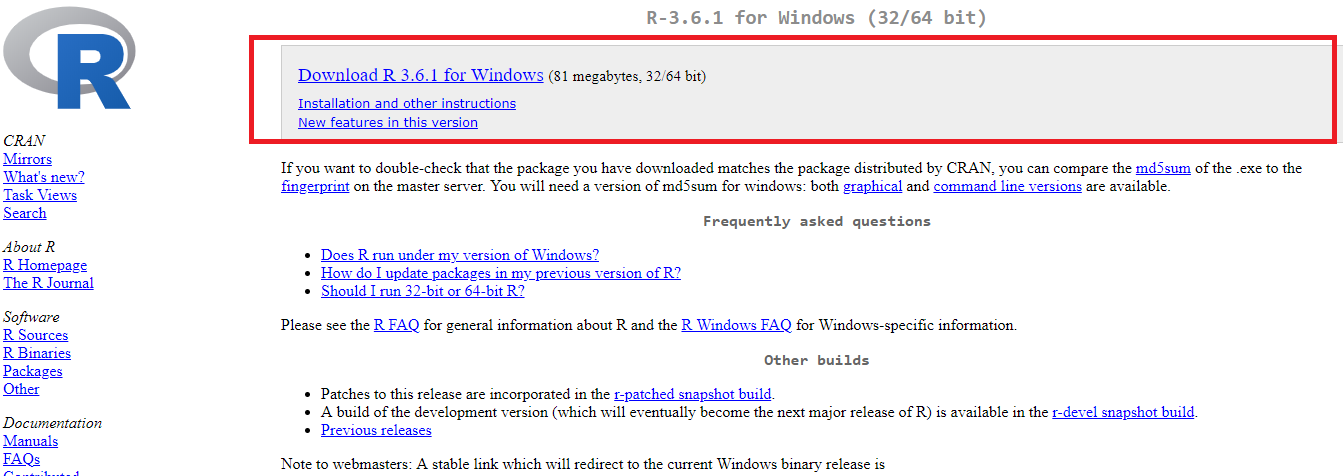
Figure 2.3: Download R para Windows
- Salve o arquivo de instalação em algum caminho de interesse do seu computador. Por exemplo, na Figura 2.4 mostra que a pasta é “Downloads.”
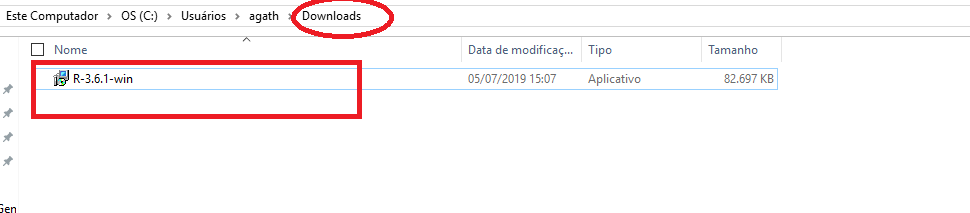
Figure 2.4: Instalador
- Clique duas vezes com o botão esquerdo no instalador para iniciar a instalação. O próximo passo é escolher a língua para instalação. Na Figura 2.5 abaixo é português.
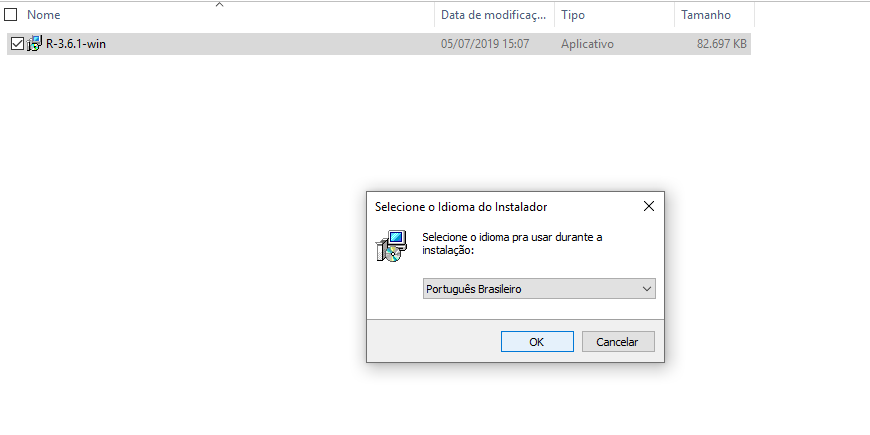
Figure 2.5: Escolha da lingua para instalação
Figure 2.6: Próximo
Figure 2.7: Próximo
Figure 2.8: Próximo
Figure 2.9: Próximo
Figure 2.10: Próximo
Figure 2.11: Próximo
- Pronto, agora o software R será instalado, como na Figura 2.12. Quando terminar, aparecerá uma janela como apresentado na Figura 2.13.
Figure 2.12: Instalação do R
Figure 2.13: Pronto: R instalado
2.3.1.2 Para MAC
Os passos para instalar o R quando o sistema operacional é OS X (Mac) são os seguintes:
- Entre no site e clique em Download R for (MAC) OS X, conforme destacado abaixo em retângulo vermelho na Figura 2.14.
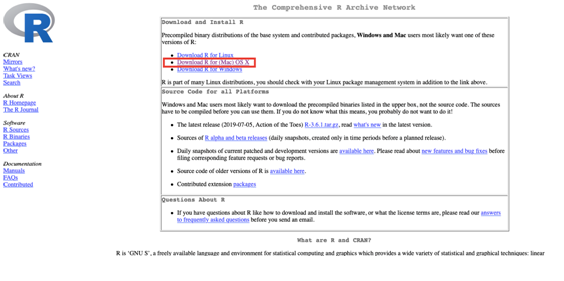
Figure 2.14: Download R para Mac
- Baixe o pacote R-3.6.1.pkg clicando no link indicado no retângulo vermelho na Figura 2.15. Note que o 3.6.1 é o número da versão mais recente disponível no momento da confecção deste material.

Figure 2.15: Download R para Mac
- Caso você não tenha configurado a pasta de descargas, o pacote será baixado na pasta “Downloads,” como mostrado na seguinte Figura 2.16. Observe que dois arquivos são baixados, clique duas vezes no arquivo “R-3.6.1.pkg” para abrir o assistente de instalação que o guiará durante o processo.
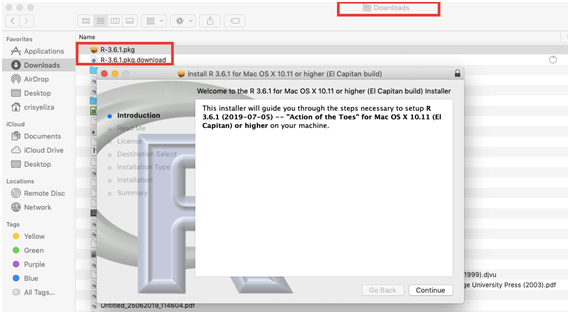
Figure 2.16: Pasta para instalação
- Acompanhe os passos indicados pelo instalador (Figura 2.17).
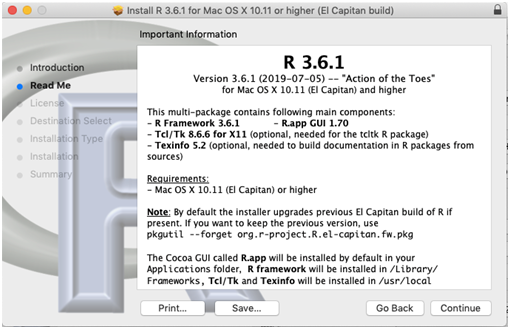
Figure 2.17: Instalação
- Deve concordar com os termos da licença, clique em “Agree” (Figura 2.18).
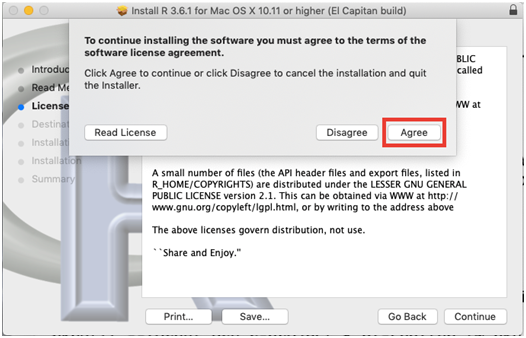
Figure 2.18: Instalação
- Selecione o lugar onde instalará o programa, no caso de ter o disco particionado e assim desejar instalar em uma parte específica. Caso contrário, continue (Figura 2.19 e 2.20).
Figure 2.19: Instalação
Figure 2.20: Instalação
- Para finalizar a instalação, o assistente lhe pedirá nome de usuário e senha do seu notebook, como apresentado na Figura 2.21.
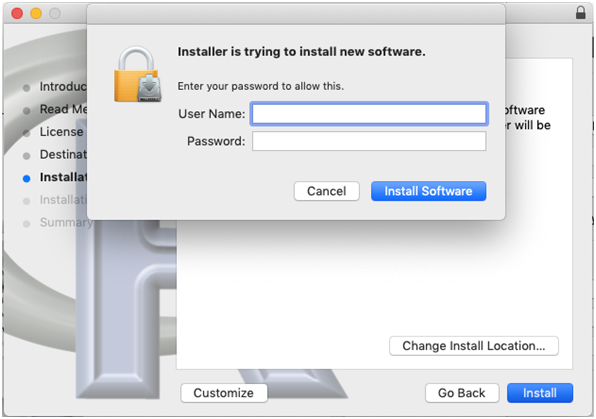
Figure 2.21: Instalação
- Pronto, agora o software R será instalado, como na Figura 2.22. Quando terminar, aparecerá uma janela como apresentado na Figura 2.23.
Figure 2.22: Instalação
Figure 2.23: Instalação
2.3.1.3 Para Linux
A instalação do R no Linux depende da distribuição utilizada. Entre neste link para acessar a página do R e clique em Download R for Linux, como no link destacado em retângulo vermelho na Figura 2.24. Em seguida, clique no link referente à distribuição utilizada (Figura 2.25).
Figure 2.24: Download em Linux
Figure 2.25: Download em Linux
2.3.2 Instalação RStudio
O RStudio é um conjunto de ferramentas integradas projetadas (IDE - Integrated Development Environment) da linguagem R para auxiliar na produtividade ao utilizar o R.
2.3.2.1 Para Windows
Figure 2.26: Site para download do RStudio
- Clique no instalador em destaque na Figura 2.27.
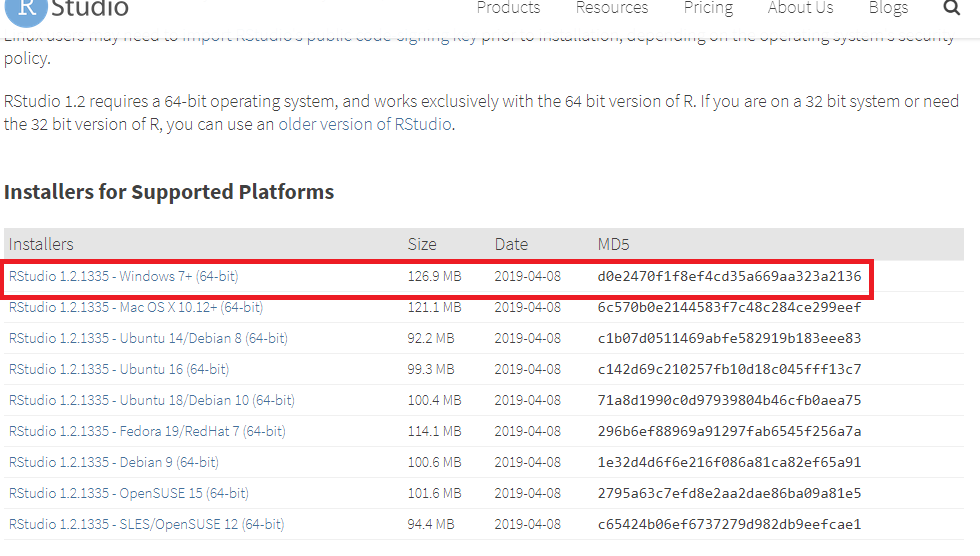
Figure 2.27: Link para download do RStudio
- Ao clicar no link, será feito o download do instalador e salvo na pasta de interesse. No caso da Figura 2.28, o instalador está na pasta Downloads. Dê dois cliques no botão esquerdo no arquivo para iniciar o download do arquivo.
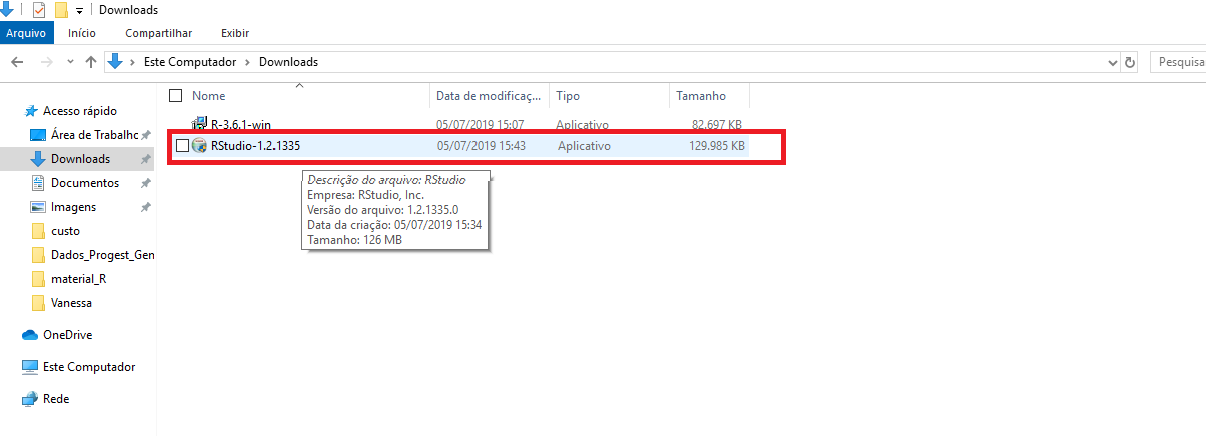
Figure 2.28: Instalador
Figure 2.29: Instalação
Figure 2.30: Instalação
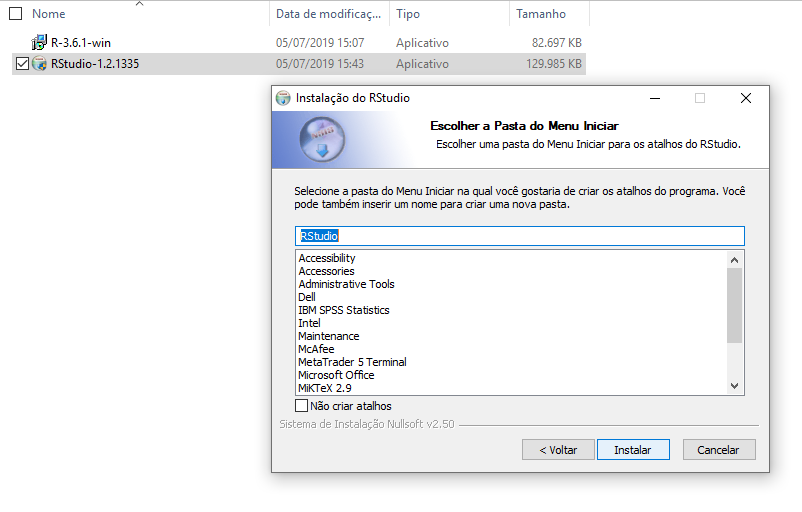
Figure 2.31: Instalação
- Pronto, a instalação será iniciada, como na Figura 2.32.
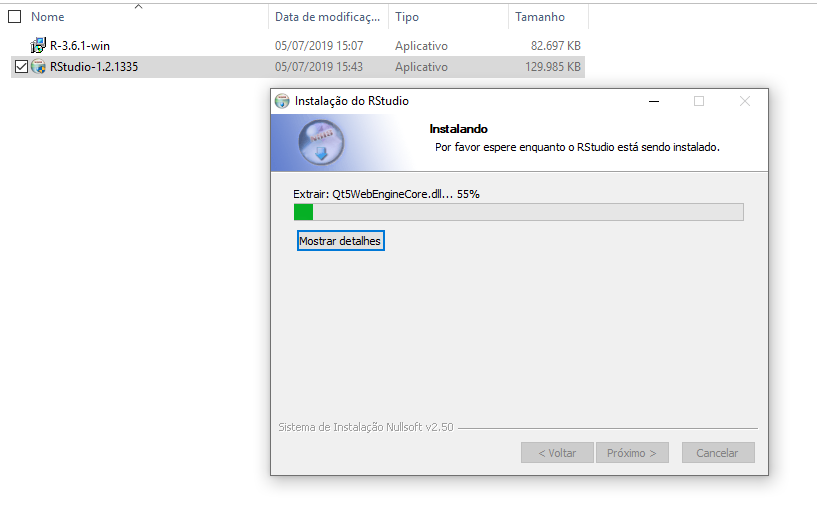
Figure 2.32: Instalação
2.3.2.2 Para MAC
Figure 2.33: Site para download do RStudio
- Clique no instalador como destacado na Figura 2.34.
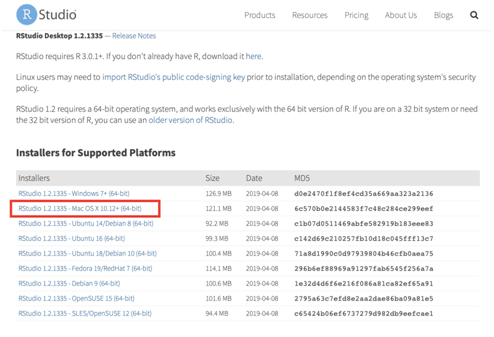
Figure 2.34: Site para download do RStudio para Mac
- Ao clicar no link, será feito o download do instalador e salvo na pasta de interesse. Caso você não tenha configurado a pasta de descargas, o instalador ficará na pasta “Downloads,” como na Figura 2.35.
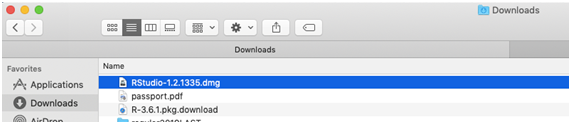
Figure 2.35: Instalador salvo em pasta
- Clicando duas vezes no arquivo “RStudio-1.2.1335.dmg” (versãos mais atual do RStudio), será feita a descarga do mesmo abrindo a janela conforme na Figura 2.36. Clique no aplicativo de RStudio destacado em vermelho também na Figura 2.36.
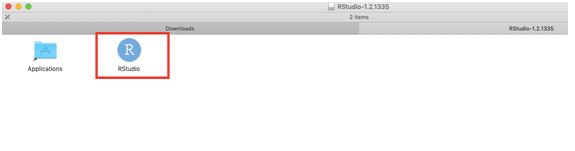
Figure 2.36: Instalação
- O instalador pode perguntar se está seguro que o aplicativo será baixado da internet e clique em “Open” (Figura 2.37).
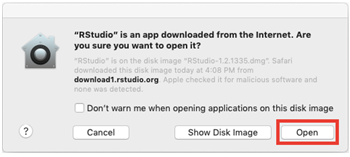
Figure 2.37: Instalação
- Pronto! Imediatamente abre o RStudio, como na Figura 2.38, e você já pode utilizá-lo.
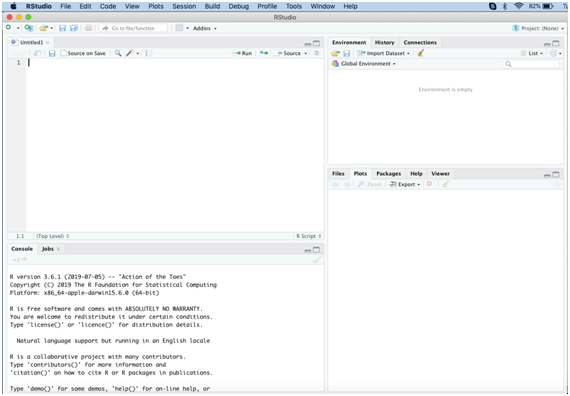
Figure 2.38: Instalação
2.4 Primeiros passos com R e RStudio
2.4.1 Primeiros contatos com RStudio
O RStudio é um conjunto de ferramentas integradas projetadas (IDE - Integrated Development Environment) da linguagem R para editar e executar os códigos em R.
Tem quatro áreas, conforme a Figura 2.41.
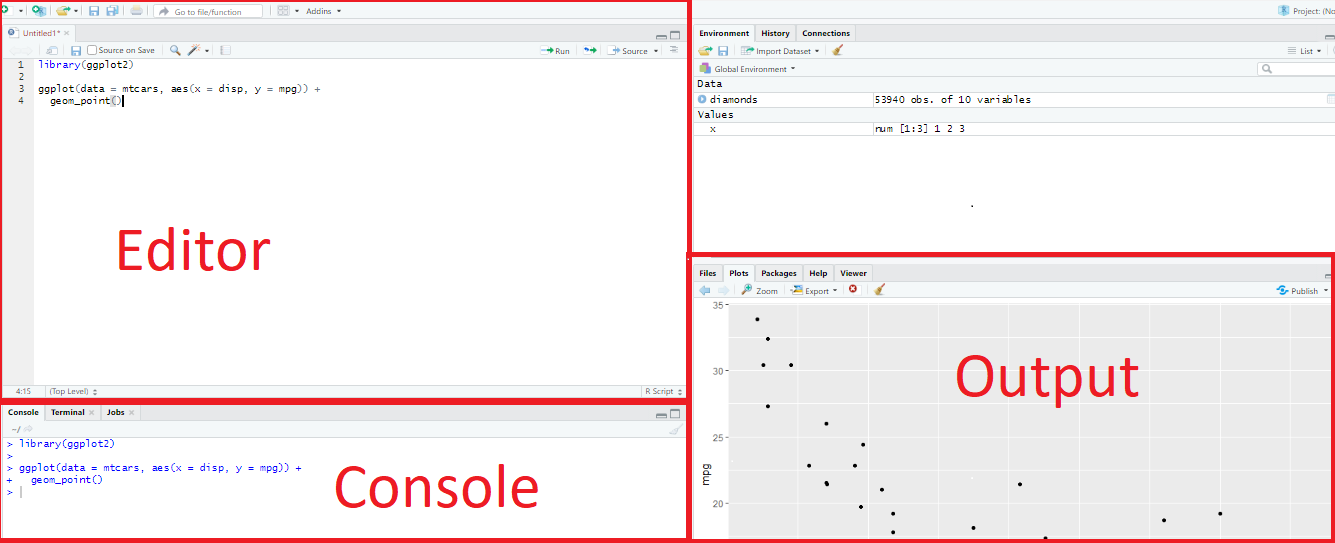
Figure 2.41: Visualização do RStudio
A seguir descrevemos melhor os painéis e abas do RStudio:
Editor/Scripts: é onde escrever os códigos. Arquivos do tipo .R.
Console: executar os comandos e ver os resultados.
Enviroment: painel com todos os objetos criados.
History: história dos comandos executados.
Files: navegar em pastas e arquivos.
Plots: onde os gráficos serão apresentados.
Packages: pacotes instalados (sem ticar) e habilitados (ticados).
Help: retorna o tutorial de ajuda do comando solicitado com help() ou ?comando. Ver melhor como pedir ajuda no R no final deste capítulo.
O usuário pode alterar a aparência do RStudio, como fonte e cor. Como exemplo, as Figuras 2.42 e 2.43 apresentam os passos para mudar o tema do script. No exemplo, deixar com fundo preto.
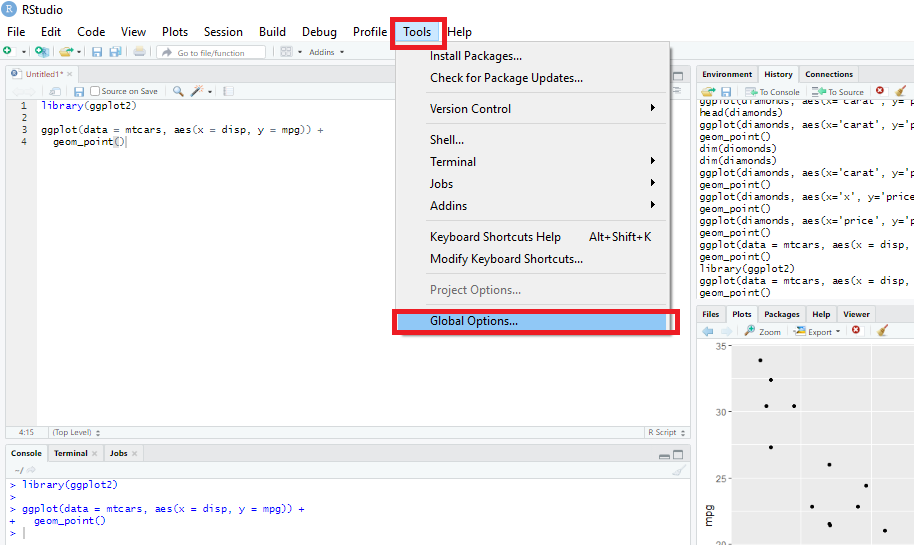
Figure 2.42: Ferramentas de aparência do RStudio
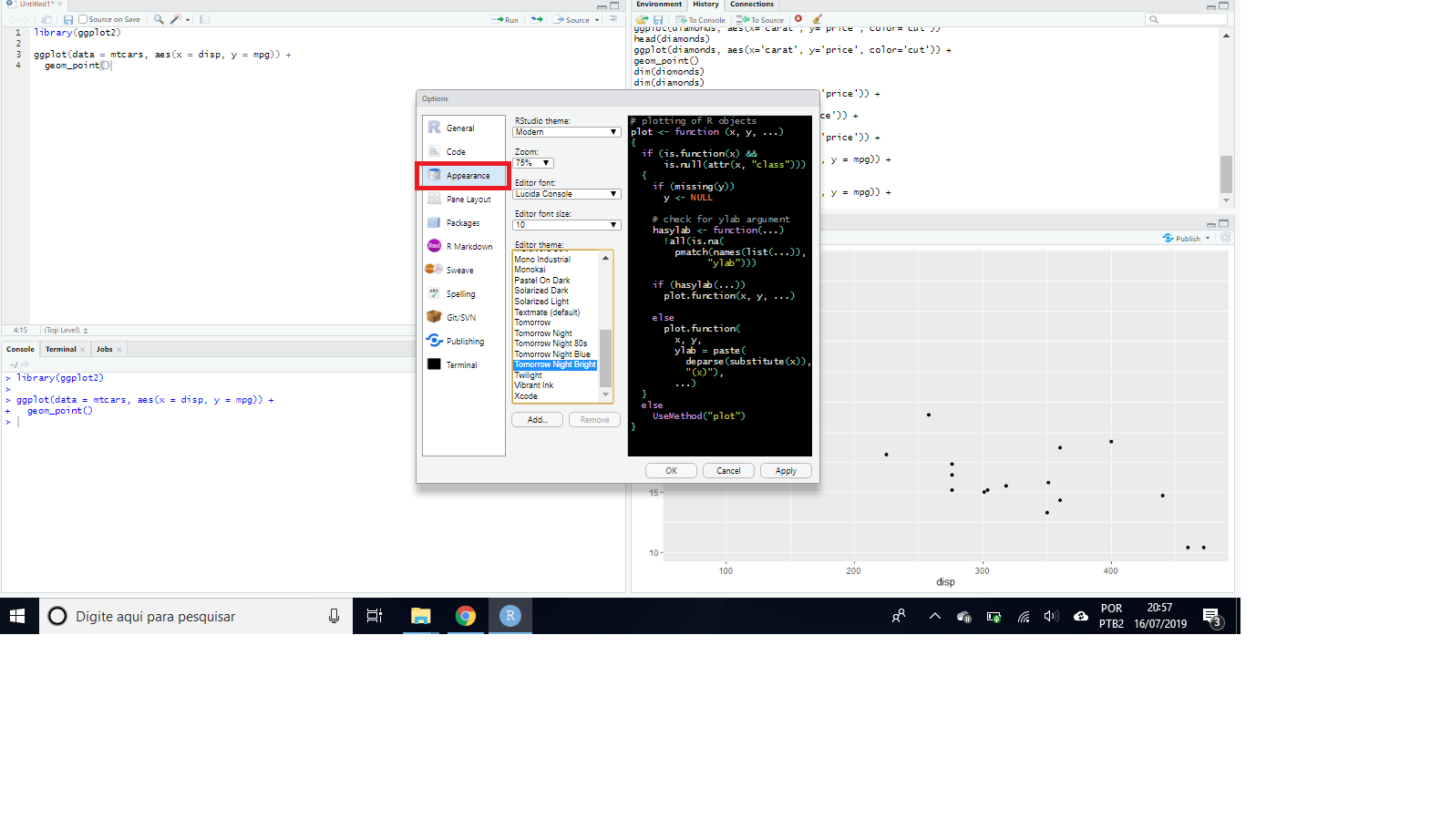
Figure 2.43: Ferramentas de aparência do RStudio
Ainda no menu Tools –> Global Options –> Pane Layout, o usuário pode organizar a ordem dos quadrantes do RStudio, como apresentado nas Figuras 2.44, 2.45 e 2.46. No exemplo, o painel Console foi transferido para o lado do painel Script, o que facilita a visualização dos comandos rodados.
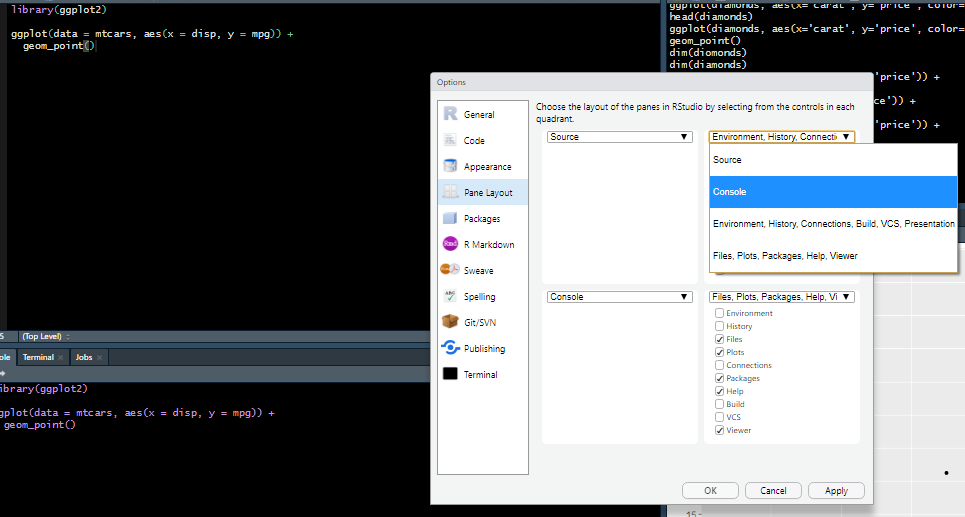
Figure 2.44: Ferramentas de aparência do RStudio
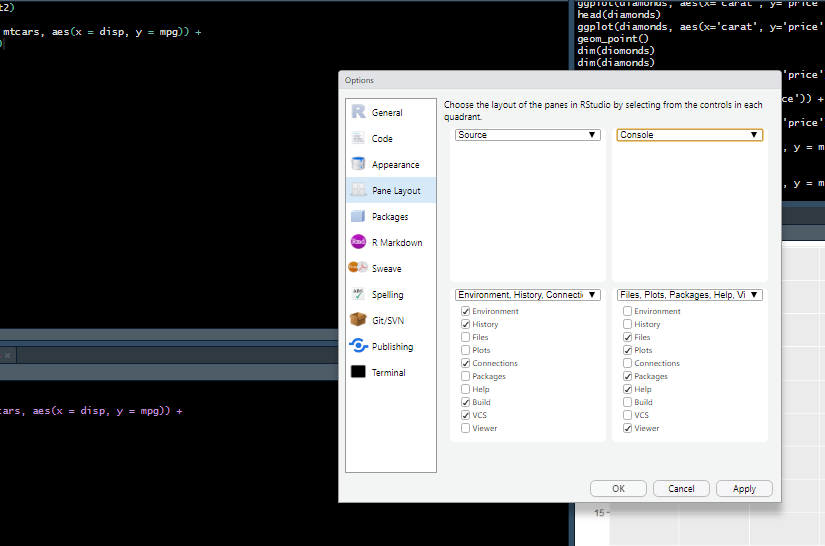
Figure 2.45: Ferramentas de aparência do RStudio
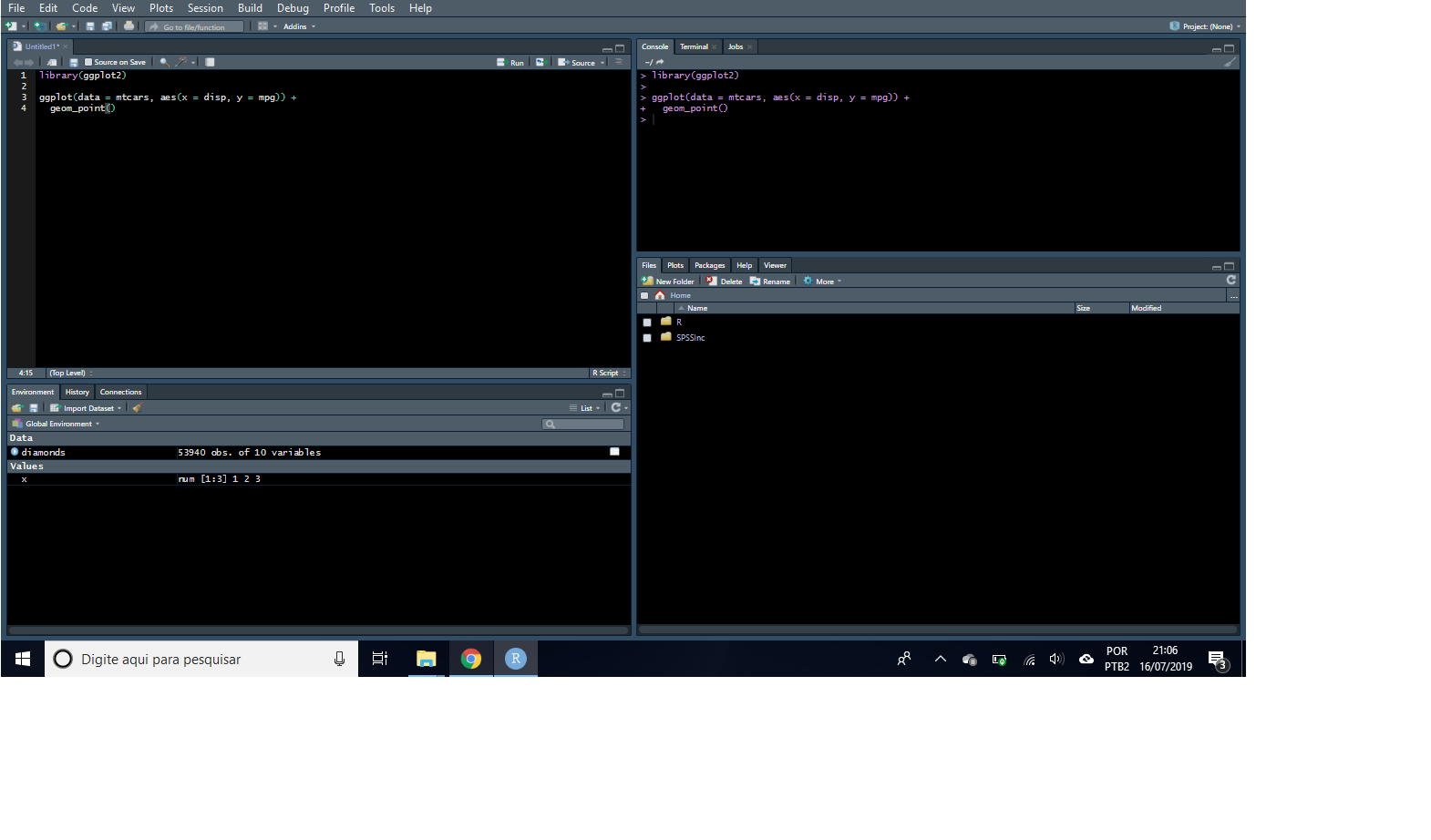
Figure 2.46: Ferramentas de aparência do RStudio
2.4.1.1 Projetos
Uma funcionalidade importante é a criação de projetos, permitindo dividir o trabalho em múltiplos ambientes, cada um com o seu diretório, documentos e workspace.
Para criar um projeto, os seguintes passos podem ser seguidos:
Clique na opção “File” do menu, e então em “New Project.”
Clique em “New Directory.”
Clique em “New Project.”
Escreva o nome do diretório (pasta) onde deseja manter seu projeto, exemplo: “my_project.”
Clique no botão “Create Project.”
Para criar um novo script para escrever os códigos, vá em File -> New File -> R Script
2.4.1.2 Boas práticas
Comente bem o seu código: é possível fazer comentários usando o símbolo ‘#.’ É sempre bom explicar o que uma variável armazena, o que uma função faz, por que alguns parâmetros são passados para uma determinada função, qual é o objetivo de um trecho de código etc.
Evite linhas de código muito longas: usar linhas de código mais curtas ajuda na leitura do código.
Escreva um código organizado. Por exemplo, adote um padrão no uso de minúsculas e maiúsculas, uma lógica única na organização de pastas e arquivos, pode ser adotada uma breve descrição (como comentário) indicando o que um determinado script faz.
Carregue todos os pacotes que irá usar sempre no início do arquivo: quando alguém abrir o seu código será fácil identificar quais são os pacotes que devem ser instalados e quais dependências podem existir.
2.4.2 Primeiros passos no R
Posso escrever o código no Script e submetê-lo ao apertar o botão “Run” ou com o atalho no teclado Cmd/Ctrl+Enter.
2.4.2.1 R como calculadora
- Operadores
#adição
10+15## [1] 25#subtração
10-2## [1] 8#multiplicação
2*10## [1] 20#divisão
30/2## [1] 15#raiz quadrada
sqrt(4)## [1] 2#potência
2^2## [1] 4Se você digitar um comando incompleto, como 10 *, o R mostrará um +. Isso não tem a ver com a soma e apenas que o R está esperando você completar seu comando. Termine seu comando ou aperte Esc para recomeçar.
Vale também ressaltar que se você digitar um comando que o R não reconhece, ele retornará uma mensagem de erro e você pode digitar outro comando normalmente em seguida.
2.4.2.2 Atribuição
Podemos salvar valores dentro de um objeto, que é simplemente um nome que guarda um valor, vetor, matriz, lista ou base de dados.
Para atribuir a um objeto, o sinal de atribuição é = ou <- (preferível).
Exemplos:
x <- 10/2
x## [1] 5X## Error in eval(expr, envir, enclos): objeto 'X' não encontradoPor que tivemos um erro acima?
O R é case sensitive, isto é, faz a diferenciação entre as letras minúsculas e maiúsculas. Portanto, x é diferente de X.
2.4.2.3 Objetos em R
Existem cinco classes básicas no R:
character: “UAH!”
numeric: 0.95 (números reais)
integer: 100515 (inteiros)
complex: 2 + 5i (números complexos, a + bi)
logical: TRUE (booleanos, TRUE/FALSE)
Vamos atribuir a x a string banana.
x <- banana ## Error in eval(expr, envir, enclos): objeto 'banana' não encontradox <- "banana"
x## [1] "banana"O primeiro caso (x <- banana) não deu certo, pois ele entendeu que estamos atribuindo a x outro objeto banana, que não foi declarado. Para atribuir o string banana a x, precisamos colocar entre aspas ou aspas simples. Uma string sem aspas é entendido como um objeto, veja abaixo:
banana <- 30
x <- banana
x## [1] 30Para saber a classe de um objeto, use a função class().
y <- "ola"
class(y)## [1] "character"x <- 2.5
class(x)## [1] "numeric"2.4.2.4 Apagar objetos
E se eu quiser apagar um objeto?
x <- 20
x## [1] 20remove(x)
x## Error in eval(expr, envir, enclos): objeto 'x' não encontradoE se eu quiser limpar o console - apaga todos os objetos atribuídos até aqui:
rm(list=ls())2.4.2.5 Vetor
Como atribuir vários valores a um objeto? Para entrar com vários números (ou nomes, ou qualquer outro grupo de coisas), precisamos usar uma função para dizer ao programa que os valores serão combinados em um único vetor.
x <- c(2,3,4)
x## [1] 2 3 4y <- seq(1,10)
y## [1] 1 2 3 4 5 6 7 8 9 10z <- rep(1,10)
z## [1] 1 1 1 1 1 1 1 1 1 1a <- 1:10
a## [1] 1 2 3 4 5 6 7 8 9 10bicho <-c("macaco","pato","galinha","porco")
bicho## [1] "macaco" "pato" "galinha" "porco"E se quisermos visualizar o conteúdo da posição 2 no vetor bicho?
bicho[2]## [1] "pato"As operações vetoriais podem ser realizadas de maneira bastante intuitiva. Como exemplos:
x <- c(2,3,4)
x## [1] 2 3 4ops <- x-1
ops## [1] 1 2 3k <- x*2
k## [1] 4 6 8Vamos agora considerar um vetor de pesos em kg e altura em metros de 6 pessoas.
peso <- c(62, 70, 52, 98, 90, 70)
peso## [1] 62 70 52 98 90 70altura <- c(1.70, 1.82, 1.75, 1.94, 1.84, 1.61)
altura## [1] 1.70 1.82 1.75 1.94 1.84 1.61Vale mencionar que o separador de decimais no R é . (ponto)!
Como calcularia o IMC? Lembrando que o IMC é dado pelo peso (em kg) dividido pela altura (em metros) ao quadrado.
imc <- peso/(altura^2)
imc## [1] 21.45329 21.13271 16.97959 26.03890 26.58318 27.00513Para saber o tamanho do vetor, use a função length().
length(imc)## [1] 62.4.2.6 Matrizes
Matrizes são vetores numéricos com duas dimensões, que são simplesmente a linha e a coluna às quais o elemento pertence.
x <- matrix(seq(1,16), nrow=4,ncol=4)
x## [,1] [,2] [,3] [,4]
## [1,] 1 5 9 13
## [2,] 2 6 10 14
## [3,] 3 7 11 15
## [4,] 4 8 12 16Note que os números de 1 a 16 foram dispostos na matriz coluna por coluna ou seja, preenchendo de cima para baixo e depois da esquerda para a direita.
Como sei qual elemento está na segunda linha e terceira coluna da matriz x?
x[2,3]## [1] 10x[3, ] # seleciona a 3ª linha## [1] 3 7 11 15x[ , 2] # seleciona a 2ª coluna## [1] 5 6 7 8x[1, 2] # seleciona o elemento da primeira linha e segunda coluna## [1] 5E se eu quiser substituir a primeira linha por (13,15,19,30)?
x[1,] <- c(13,15,19,30)
x## [,1] [,2] [,3] [,4]
## [1,] 13 15 19 30
## [2,] 2 6 10 14
## [3,] 3 7 11 15
## [4,] 4 8 12 16Seja o vetor d:
d <- c(128,124,213,234)E se quisermos substituir a terceira coluna por d?
x[,3] <- dQual a dimensão da matriz x?
Vimos que para vetor usamos o comando length(). Serve para matriz também? Vamos testar!
length(x)## [1] 16Note que retorna o número de colunas vezes o número de linhas (4*4=16). Mas o que quero saber é o numero de linhas e de colunas. Para isso, o comando é dim().
dim(x)## [1] 4 4Para concatenar linhas em uma matriz, podemos usar o comando rbind():
vet <- c(2,20,12,34)
x2 <- rbind(x,vet)
x2## [,1] [,2] [,3] [,4]
## 13 15 128 30
## 2 6 124 14
## 3 7 213 15
## 4 8 234 16
## vet 2 20 12 34Para concatenar colunas em uma matriz, podemos usar o comando cbind():
v2 <- c(25,10,15,4)
x3 <- cbind(x,v2)
x3## v2
## [1,] 13 15 128 30 25
## [2,] 2 6 124 14 10
## [3,] 3 7 213 15 15
## [4,] 4 8 234 16 42.4.2.7 Fator
Fatores podem ser vistos como vetores de inteiros que possuem rótulos (labels). Eles são úteis para representar uma variável categórica (nominal e ordinal).
sexo <- c("M", "H", "H", "H", "M", "M", "H")
sex <- as.factor(sexo)
sex## [1] M H H H M M H
## Levels: H Mlevels(sex)## [1] "H" "M"2.4.2.8 Data frame
Trata-se de uma “tabela de dados” onde as colunas são as variáveis e as linhas são os registros. Essas colunas podem ser de classes diferentes.
Essa é a grande diferença entre data.frame’s e matrizes (matriz é só numerica).
Posso criar um data frame no R com os vetores, por exemplo:
ID <- seq(1,6)
pes <- c(62, 70, 52, 98, 90, 70)
alt <- c(1.70, 1.82, 1.75, 1.94, 1.84, 1.61)
imc <- pes/(alt^2)
dados <- data.frame(ID=ID,peso=pes,altura=alt, imc=imc)
dados## ID peso altura imc
## 1 1 62 1.70 21.45329
## 2 2 70 1.82 21.13271
## 3 3 52 1.75 16.97959
## 4 4 98 1.94 26.03890
## 5 5 90 1.84 26.58318
## 6 6 70 1.61 27.00513Posso pensar que o data frame tem a mesma ideia de matriz. Quero olhar os dados de altura, que sei que está na coluna 3.
dados[,3]## [1] 1.70 1.82 1.75 1.94 1.84 1.61Mas existe uma maneira mais fácil de selecionar a variável de interesse sem ter que saber em qual coluna ela está.
Por ser um data frame, posso usar $ da seguinte maneira:
dados$altura## [1] 1.70 1.82 1.75 1.94 1.84 1.61Putz, esqueci de colocar a variável de grupo no data frame. Tenho que criar tudo de novo? Não:
gr <- c(rep(1,3),rep(2,3))
dados$grupo <- gr
dados## ID peso altura imc grupo
## 1 1 62 1.70 21.45329 1
## 2 2 70 1.82 21.13271 1
## 3 3 52 1.75 16.97959 1
## 4 4 98 1.94 26.03890 2
## 5 5 90 1.84 26.58318 2
## 6 6 70 1.61 27.00513 2Veja que no “dados$grupo” foi inserido o objeto “gr.” Se “gr” não tivesse o mesmo número de linhas do data frame retornaria um erro.
Funções úteis para data.frame:
Ainda não falamos com muito detalhes sobre funções no R, faremos isso mais adiante. Mas por enquanto, considere que sejam nomes já salvos no R e que, ao colocar o objeto da base de dados (no nosso exemplo é dados) dentro dos parênteses, retorna algumas informações úteis sobre a base de dados. São algumas delas:
head() - Mostra as primeiras 6 linhas.
tail() - Mostra as últimas 6 linhas.
dim() - Número de linhas e de colunas.
names() - Os nomes das colunas (variáveis).
str() - Estrutura do data.frame. Mostra, entre outras coisas, as classes de cada coluna.
head(dados)## ID peso altura imc grupo
## 1 1 62 1.70 21.45329 1
## 2 2 70 1.82 21.13271 1
## 3 3 52 1.75 16.97959 1
## 4 4 98 1.94 26.03890 2
## 5 5 90 1.84 26.58318 2
## 6 6 70 1.61 27.00513 2dim(dados)## [1] 6 5names(dados)## [1] "ID" "peso" "altura" "imc" "grupo"str(dados)## 'data.frame': 6 obs. of 5 variables:
## $ ID : int 1 2 3 4 5 6
## $ peso : num 62 70 52 98 90 70
## $ altura: num 1.7 1.82 1.75 1.94 1.84 1.61
## $ imc : num 21.5 21.1 17 26 26.6 ...
## $ grupo : num 1 1 1 2 2 22.4.2.9 Operadores lógicos
A operação lógica nada mais é do que um teste que retorna verdadeiro (TRUE) ou falso (FALSE). Esses dois valores recebem uma classe especial: logical.
- Igual a: ==
Vamos testar se um valor é igual ao outro.
Exemplo:
10==11## [1] FALSE11==11## [1] TRUENo primeiro retornou FALSE, pois realmente 10 não é igual a 11 e no segundo caso acima retornou TRUE, pois realmente 11 é igual a 11.
De maneira análoga funciona para os operadores abaixo:
- Diferente de: !=
Exemplo:
10!=11## [1] TRUEMaior que: >
Maior ou igual: >=
Menor que: <
Menor ou igual: <=
Exemplos:
10>5## [1] TRUE10>=10## [1] TRUE4<4## [1] FALSE4<=4## [1] TRUE- Um outro operador muito útil é o
%in%. Com ele, podemos verificar se um valor está dentro de um vetor.
ex <- 1:15
3 %in% ex## [1] TRUE- E: & - será verdadeiro se os dois forem TRUE.
x <- 15
x > 10 & x < 30## [1] TRUEx < 10 & x < 30## [1] FALSE- OU: | - será verdadeiro se um dos dois forem TRUE.
x <- 15
x > 10 | x < 30## [1] TRUEx < 10 | x < 30## [1] TRUE- Negação: !
x <- 15
!x<30## [1] FALSE2.4.2.10 Dados faltantes, infinitos e indefinições matemáticas
- NA (Not Available): dado faltante/indisponível. Exemplo:
x <- c(1,6,9)
x[4]## [1] NARetornou NA porque não há elemento na posição 4 do vetor x.
- NaN (Not a Number): indefinições matemáticas. Como 0/0 e log(-1). Exemplo:
log(-10)## [1] NaN- Inf (Infinito): número muito grande ou o limite matemático. Aceita sinal negativo (-Inf). Exemplo:
10^14321## [1] Inf2.4.2.11 Condicionamento: If e else
As estruturas if e else servem para executar um código apenas se uma condição (teste lógico) for satisfeita.
a <- 224
b <- 225
if (a==b) {
v <- 10
} else {
v <- 15
}
v## [1] 15Veja que o R só executa o conteúdo das chaves {} se a expressão dentro dos parênteses () retornar TRUE.
Note que a condição de igualdade é representada por dois iguais (==). Como dito anteriormente, apenas um igual (=) é símbolo de atribuição (preferível <-).
Veja outro exemplo:
a <- 224
b <- 225
if (a==b) {
v <- 10
} else if (a > b) {
v <- 15
} else {
v <- 25
}
v## [1] 25Veja que nesse exemplo gostaria de usar mais de duas condições, e por isso usamos a estrutura intermediária else if.
2.4.2.12 Iterador for
O for serve para repetir uma mesma tarefa para um conjunto de valores diferentes. Cada repetição é chamada de iteração.
Como exemplo, considere o vetor atribuído ao objeto m como segue:
m <- c(1,20,50,60,100)Quero criar um novo vetor, p digamos, que seja formado por cada elemento de m dividido por sua posição.
p <- NULL
for (i in 1: length(m)){
p[i] <- m[i]/i
}
p## [1] 1.00000 10.00000 16.66667 15.00000 20.00000Note que primeiro definimos o objeto p, recebendo NULL. O NULL representa a ausência de um objeto e serve para já declarar algum objeto que receberá valor na sequência. No caso, ao rodar o for, o p é um vetor de tamanho 5 (tamanho do vetor m).
No exemplo, temos 5 iterações e para cada valor de i, correndo de 1 até 5 (tamanho de m), pegamos o valor de m na posição i e dividimos por sua posição. Assim, formamos o vetor p.
2.4.2.13 Funções
Funções no R são nomes que guardam um código de R. A ideia é que sempre que rodar a função com os seus argumentos, o código que ela guarda será executado e o resultado será retornado.
Já usamos anteriormente algumas funções que estão na base do R. Por exemplo, quando usamos class() para entender a classe do objeto que o R está entendendo. Colocamos um argumento dentro do parênteses e o R retornou qual a classe do objeto em questão. Relembre o que falamos ao perguntar ao R qual a classe do vetor oi criado:
oi <- c(10,20,2,1,0.5)
class(oi)## [1] "numeric"Agora vamos conversar sobre outra função já criada e disponibilizada na base do R: mean. Essa função retorna a média do vetor que está em seu argumento. Vamos calcular a média dos valores do vetor oi:
mean(oi)## [1] 6.7Considere que, por algum motivo, tenha no vetor oi uma observação faltante. No R, dado faltante é caracterizado por NA.
oi <- c(10,20,2,1,0.5,NA)Perceba que, apesar de NA ser um texto, não coloquei entre aspas porque quero falar para o R que naquela posição não tem valor e o R entende isso ao ler NA (sem aspas). Se colocar entre aspas, ele entenderá como sendo um texto e não mais como valor faltante.
mean(oi)## [1] NAComo não sabemos o valor do elemento na posição 6 do vetor oi, o R não teria como calcular a média de todos os 6 valores e por isso devolve NA. No entanto, queremos calcular a média dos elementos de oi ao retirar os valores faltantes, ou seja, queremos fazer: (10+20+2+1+0.5)/5. Então devemos falar para o R o que queremos, e para isso podemos utilizar o argumento na.rm = TRUE:
mean(oi,na.rm = TRUE)## [1] 6.7Importantes:
Se a função tiver mais de um argumento, eles são sempre separados por vírgulas;
Cada função tem os seus próprios argumentos. Para saber quais são e como usar os argumentos de uma função, basta acessar a sua documentação. Uma forma de fazer isso é pela função
help, cujo argumento é o nome da função que precisa de ajuda:
help(mean)Veja que abrirá a documentação sobre a função mean no menu “Help” do RStudio, e lá é possível ver os argumentos e exemplos de uso da função em questão.
Ainda sobre funções já presentes no R, vamos considerar agora a função sample. Veja a documentação dessa função para ver o que ela faz:
help(sample)A função sample retorna uma amostra de um vetor com tamanho especificado em um de seus argumentos com ou sem reposição. Ela apresenta quatro argumentos: sample(x, size, replace = FALSE, prob = NULL), em que: x é o vetor do qual será amostrado o número de elementos especificado no argumento size, seja com ou sem reposição (argumento replace) e com dadas probabilidades de seleção, especificadas em prob.
Quero usar essa função para amostrar do objeto oi (x=oi) dois elementos (size=2) em uma seleção com reposição (replace = TRUE) e que a probabilidade de seleção seja a mesma para todos os elementos do vetor oi. No caso da probabilidade, como podemos ver na documentação da função sample, o default (padrão se o usuário não mudar o argumento) é ser a mesma probabilidade de seleção para todos os elementos. Assim, se o usuário nada especificar para esse argumento, o R entenderá o seu default. O mesmo vale para o argumento replace: caso fosse o interesse fazer a seleção sem reposição, não precisaríamos colocar esse argumento porque seu default é FALSE.
sample(x=oi,size=2,replace=TRUE) #não colocamos argumento prob porque vamos usar o seu default (probs iguais).## [1] 2 20Também poderíamos usar a mesma função sem colocar o nome dos argumentos:
sample(oi,2,TRUE) ## [1] 20 20Mas, nesse caso, é importante que se respeite a ordem dos argumentos: o vetor tem que ser o primeiro, o segundo argumento é size e assim por diante.
Vale ressaltar que as duas últimas saídas não necessariamente serão as mesmas, porque é feito um sorteio aleatório de dois elementos de oi em cada uma delas.
Além de usar funções já prontas, podemos criar novas funções. Suponha que queremos criar uma função de dois argumentos que retorna o primeiro mais três vezes o segundo argumento. Criamos a função no que segue:
f_conta <- function(x,y) {
out <- x+3*y
return(out)
}A função acima tem:
o nome: f_conta;
os argumentos: x e y;
o corpo out: <- x+3*y; e
o que retorna: return(out).
Suponha que eu queira fazer a conta 10+3*20. Podemos fazer isso ao chamar a função criada f_conta.
f_conta(x=10,y=20)## [1] 70Veja que o cálculo acima retorna exatamente o mesmo que o seguinte:
f_conta(y=20,x=10)## [1] 70Isso acontece porque mudei a ordem dos argumentos, mas acompanhado com os nomes dos argumentos. Se eu não quiser colocar os nomes dos argumentos, precisa tomar cuidado para não errar a ordem deles. Pois:
f_conta(10,20)## [1] 70é diferente de
f_conta(20,10)## [1] 502.5 Como obter ajuda no R
Listamos aqui 3 maneiras para buscar ajuda no R:
- Help/documentação do R (comandos help(nome_da_funcao) ou ?nome_da_funcao). Como exemplo,
help(mean) #ou
?mean- Google
Na Figura 2.47 está o exemplo de busca de ajuda no Google. Repare no ‘r’ no início da busca, isso pode ajudar.
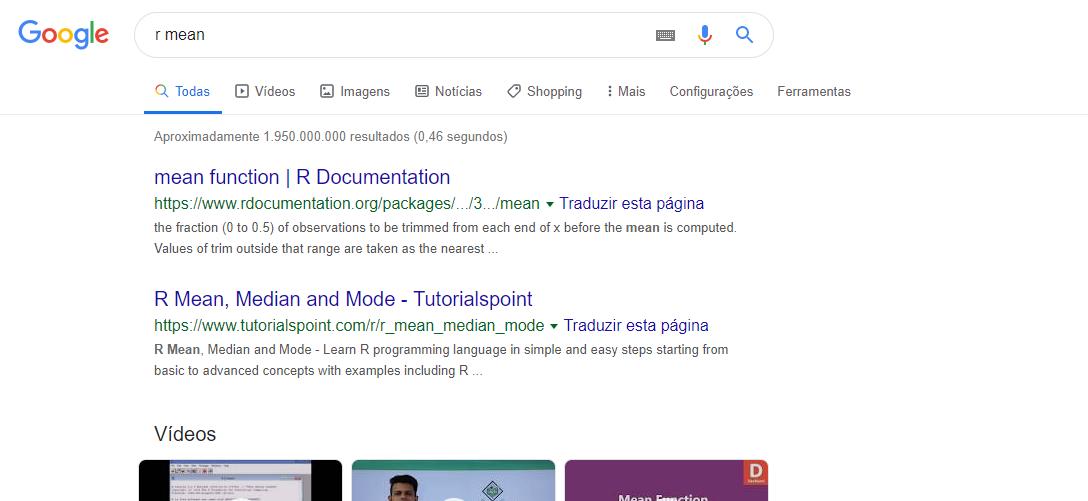
Figure 2.47: Pesquisa no Google
- Comunidade O Stack Overflow e o Stack Overflow em Português são sites de Pergunta e Resposta amplamente utilizados por todas as linguagens de programação, e o R é uma delas.
2.6 Pacotes
Como dito quando falamos “Sobre o R,” o R apresenta funções na sua base e também em forma de pacotes (conjunto de funções bem documentado), que precisam ser instalados (uma vez no seu computador) e carregados na sessão de utilização do R (carregado em toda sessão aberta).
Dificilmente você vai fazer uma análise apenas com as funções básicas do R e dificilmente não vai existir um pacote com as funções que você precisa. Por esse motivo, falamos a seguir em como instalar e carregar pacotes.
2.6.1 Instalação
- Via CRAN:
install.packages("nome-do-pacote")Exemplo: Instalação do pacote dplyr.
install.packages("dplyr")Note que o nome do pacote está entre aspas.
- Via Github:
Para instalar via Github, precisa primeiramente instalar o pacote
devtools.
devtools::install_github("nome-do-repo/nome-do-pacote")Exemplo:
devtools::install_github("tidyverse/dplyr")2.6.2 Carregar pacotes:
Uma vez que um pacote de interesse está instalado em sua máquina, para carregá-lo na sessão atual do R é só rodar a seguinte linha de comando:
library(nome-do-pacote)Veja que para carregar o pacote não se usa aspas.
Como exemplo, o carregamento do pacote dplyr:
library(dplyr)Só é necessário instalar o pacote uma vez, mas é necessário carregá-lo toda vez que começar uma nova sessão.
Dado que o pacote está carregado ao rodar a função library(), todas as funções desse pacote podem ser usadas sem problemas.
Caso você não queira carregar o pacote e apenas usar uma função específica do pacote, você pode usar nome-do-pacote::nome-da-funcao. Por exemplo:
dplyr::distinct(...)Se você tivesse carregado o pacote dplyr anteriormente (pela função library()), não seria necessário colocar dplyr:: antes da função distinct do pacote.
2.7 Materiais complementares
Critical Thinking in Clinical Research. Felipe Fregni & Ben M. W. Illigens. 2018.
Sites:
CHAPTER 3: Selecting the Study Population. In: Critical Thinking in Clinical Research by Felipe Fregni and Ben Illigens. Oxford University Press 2018.
Fandino W. Formulating a good research question: Pearls and pitfalls. Indian J Anaesth. 2019;63(8):611–616. doi:10.4103/ija.IJA_198_19
Riva JJ, Malik KM, Burnie SJ, Endicott AR, Busse JW. What is your research question? An introduction to the PICOT format for clinicians. J Can Chiropr Assoc. 2012;56(3):167–171.
External validity, generalizability, and knowledge utilization. Ferguson L1. J Nurs Scholarsh. 2004;36(1):16-22.
Peter M Rothwell; Commentary: External validity of results of randomized trials: disentangling a complex concept, International Journal of Epidemiology, Volume 39, Issue 1, 1 February 2010, Pages 94–96, https://doi.org/10.1093/ije/dyp305